quack-bot
Challenge Information
- Name: quack-bot
- Points: 10
- Category: Reverse Engineering
- Objective: Analyze a Kramer-encrypted PYC binary and its staged shellcode to extract the final payload and recover the flag.
Solution
Spotting the PYC artifact
- The
QuackBot.quackfile stands out as a PYC-compiled binary. - This sets the stage for Python bytecode-focused reversing.

- The
Decompiling with an online tool
- Used the online viewer to reverse the bytecode at https://pylingual.io/view_chimera?identifier=35d0286b3a3d4c7cb833ef6de56995ac9f8d04dafd9187347e4bd7c10c54e19a.
- The output confirmed the code was readable but still protected.
Recognizing Kramer encryption
- The decompiled output shows Kramer-style protection.
- Switched to the Kramer decryptor at https://github.com/jcarndt/kramer_decryptor/blob/main/kramer_decryptor.py.
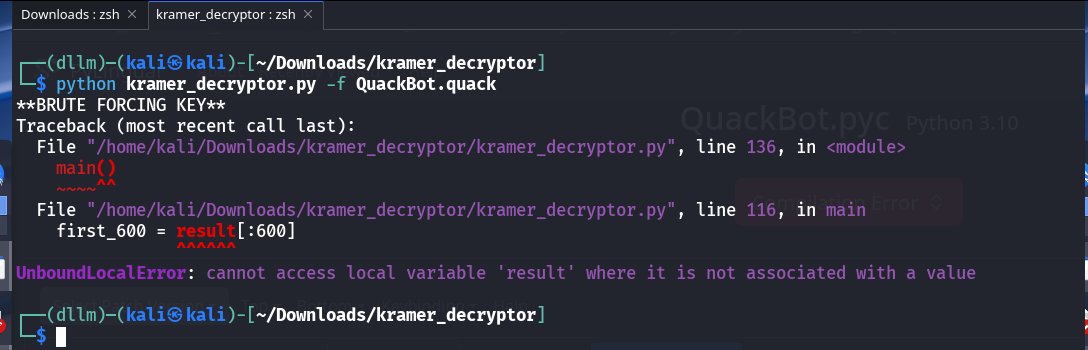
Hitting a decryptor issue
- The script failed to extract the needed
ceb6blob. - The PYC data still clearly contained the
ceb6pattern, so the extraction logic looked too strict.
- The script failed to extract the needed
Confirming the regex mismatch
- The decryptor’s pattern matching did not capture the full encrypted content.
- This mismatch blocked further progress until the regex was adjusted.

Relaxing the regex and updating the script
- The regex was loosened to capture the
ceb6 ... )blob reliably. - With this change, the decryptor could extract and process the encrypted data.
- The regex was loosened to capture the
| |
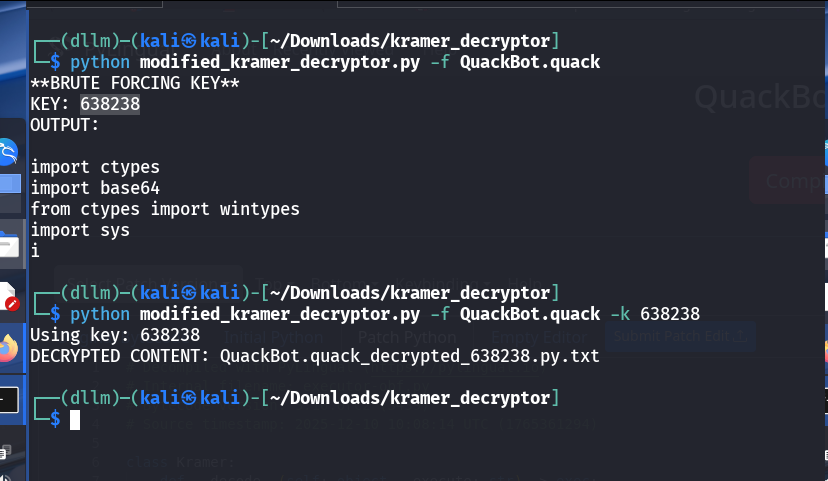
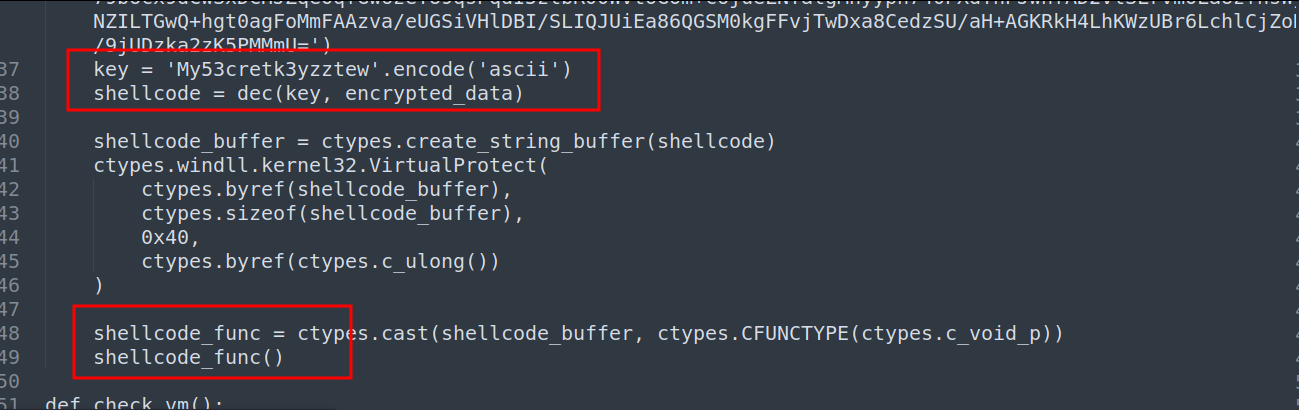
Seeing shellcode execution
- The decrypted output shows the next stage runs shellcode.
- That pushed the analysis toward shellcode behavior instead of Python logic.
Converting shellcode to an EXE
- Emulation with scdbg did not work.
- The shellcode was converted to an executable with https://github.com/accidentalrebel/shcode2exe.


Recreating the API hash logic
- The loader avoids plaintext API strings and skips direct
GetProcAddressusage. - It computes a 64-bit hash from module and export names and compares XORed pairs against constants.
- A script was written to reproduce the hashing routine and map constants back to real API names.
- The loader avoids plaintext API strings and skips direct
| |

- Assuming likely API targets
- Dynamic API resolution suggests common calls like
VirtualAlloc(). - This points to a staged payload being copied into memory.
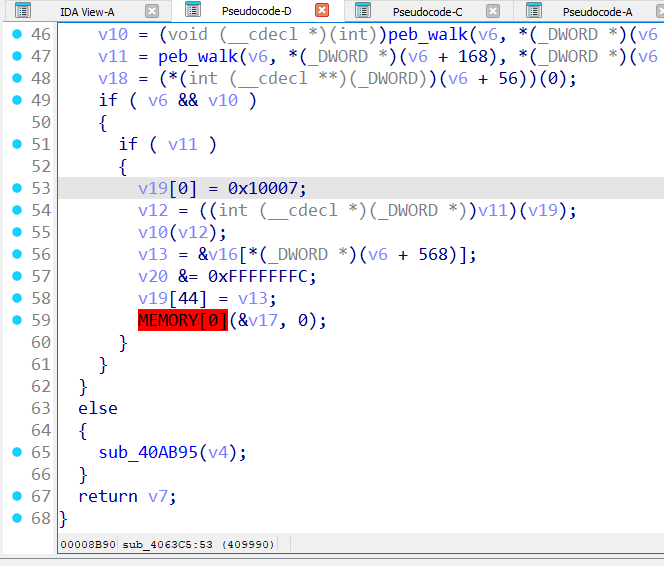
- Finding the next routine
- Debugging shows a call into
sub_40ab95(). - That call anchors the next stage of analysis.
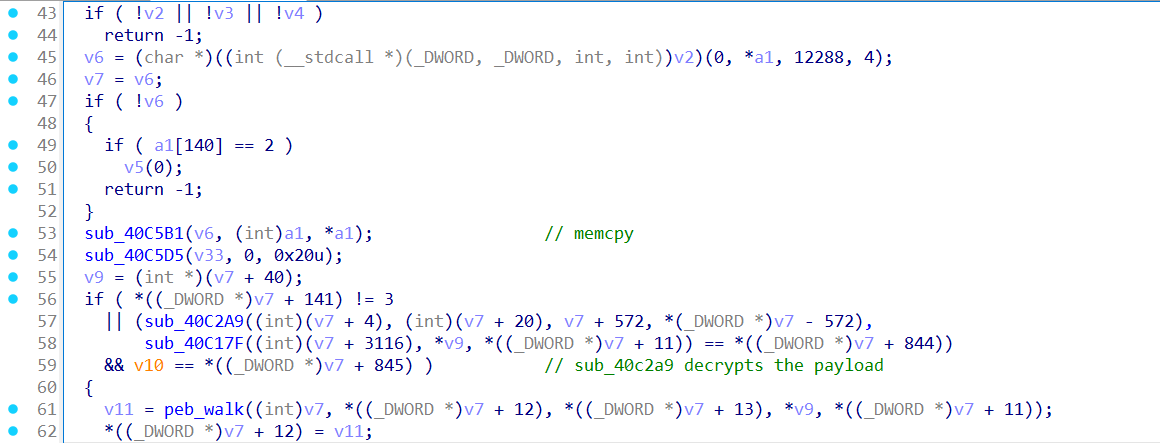
- Tracing payload copy and decrypt
sub_40C5B1()copies a large blob into memory atv6(0x1a0000).sub_40C2A9()then decrypts that payload.
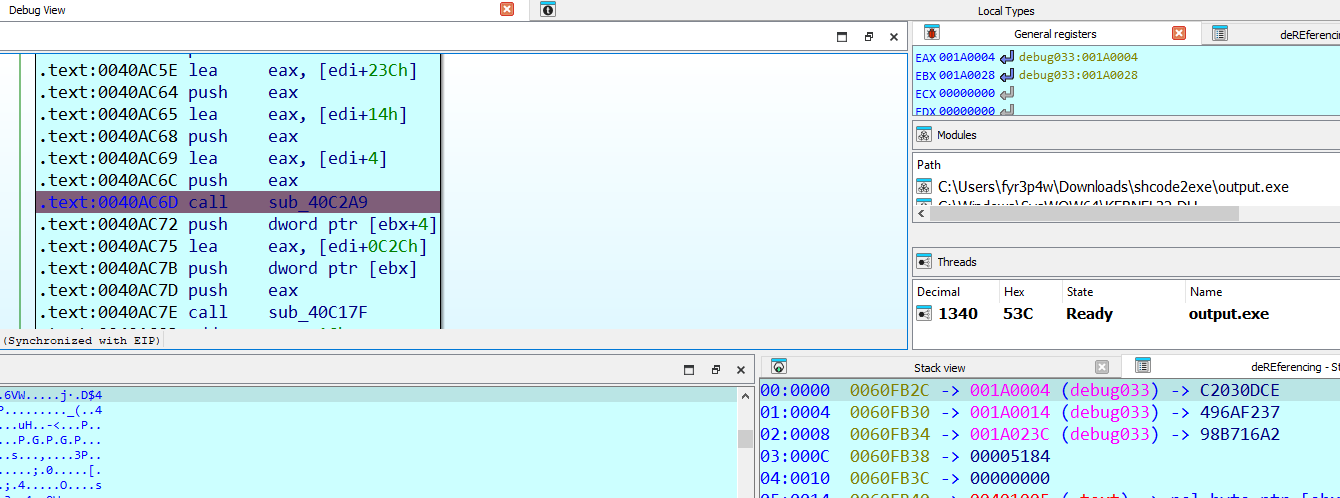
- Preparing a memory dump
- A breakpoint at
sub_40C2A9()reveals argument 1 as the key, argument 2 as the IV, and argument 3 as the destination buffer. - The target region to dump is
0x001B023Cwith a length of0x5184bytes.
| |
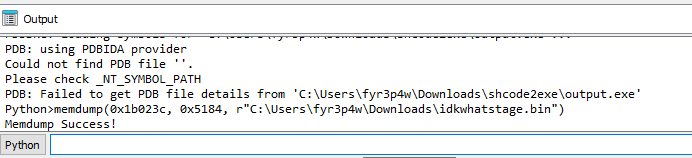
- Dumping after decryption
- The IDA script was used right after
sub_40C2A9()completed. - This produced the decrypted blob for the next step.
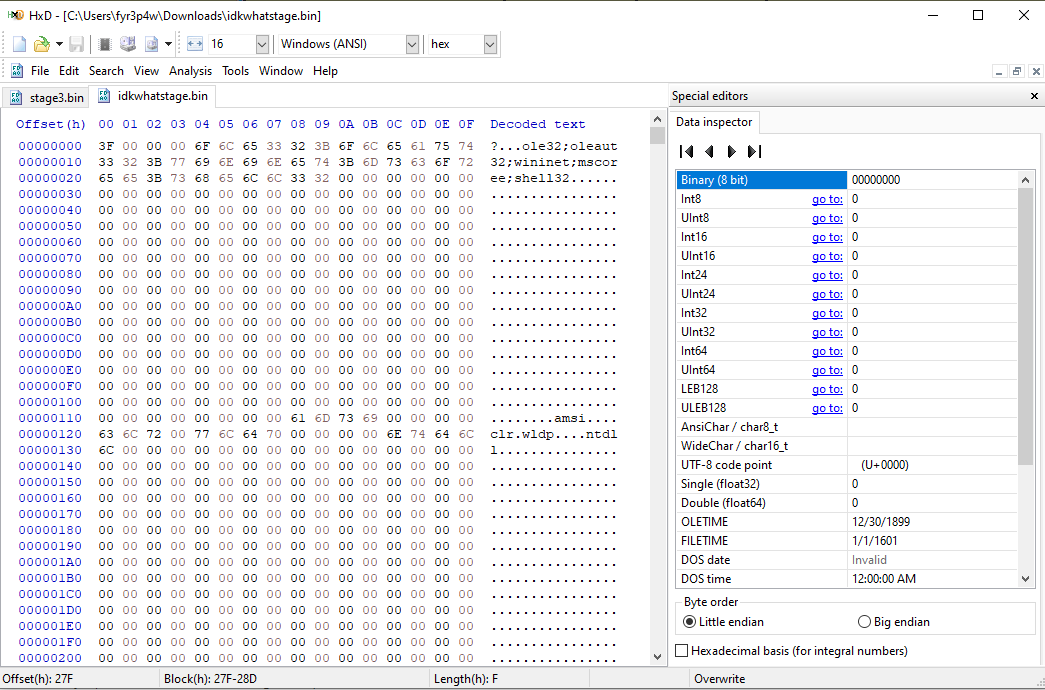
- Reading the dumped strings
- The dumped data contains readable strings now.
- That confirms the decryption worked as expected.
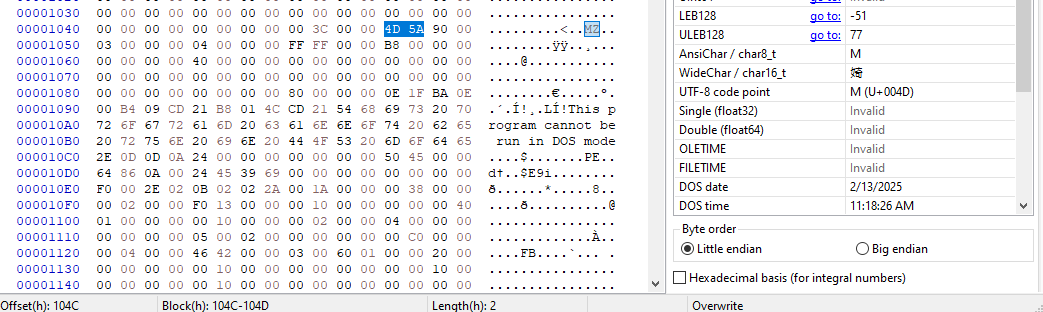
- Handling a non-EXE stage
- The extracted
idkwhatstage.binis not a valid EXE. - Binwalk failed to extract it automatically.
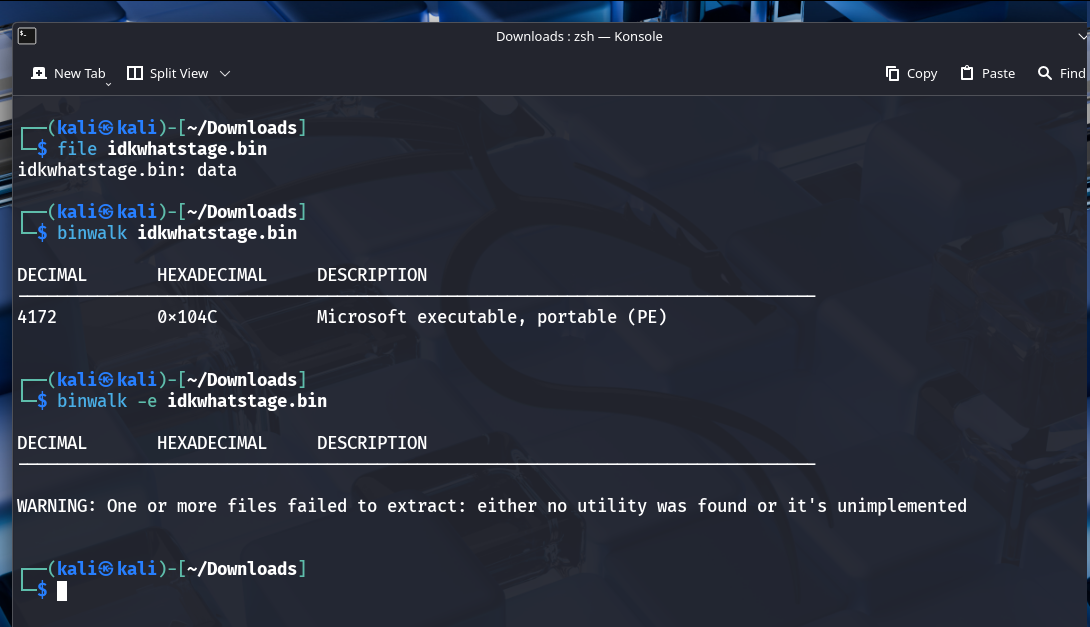
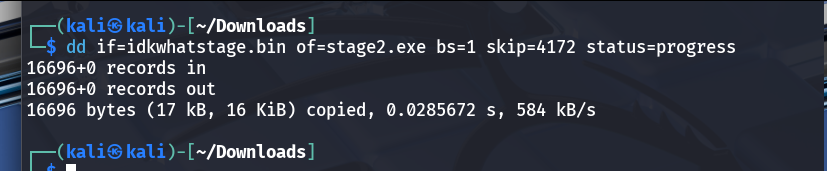
- Force-extracting the next binary
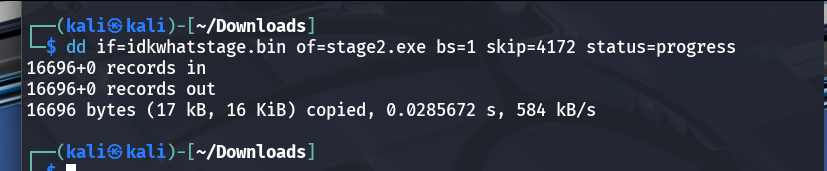
- Manual extraction was done with
dd if=idkwhatstage.bin of=stage2.exe bs=1 skip=4172 status=progress. - The resulting
stage2.exeis the next payload to inspect.
- Identifying bind shell behavior
- The new binary opens a TCP listener and launches
cmd.exe. - That behavior matches a bind shell stage.
- Spotting odd IP addresses
off_140003000contains a list of invalid-looking IPs.- The format hints at octal-encoded bytes rather than real dotted decimals.
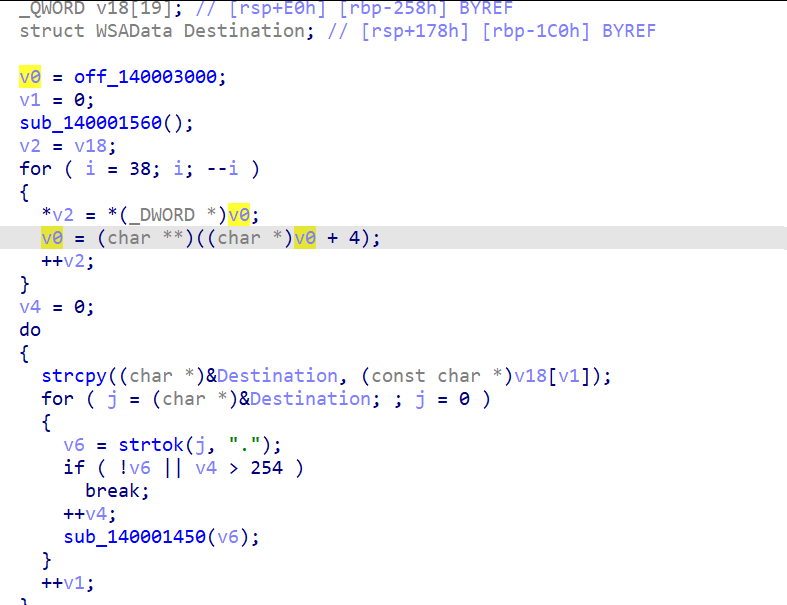
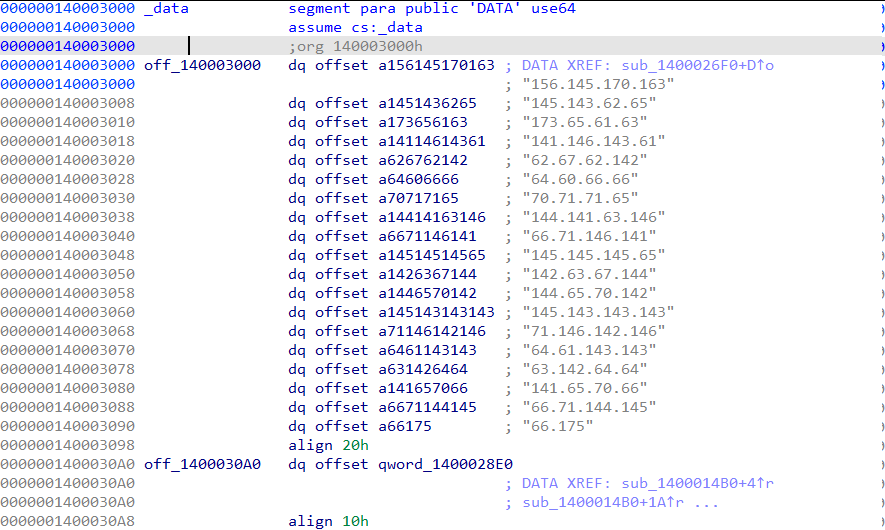
- Decoding octal to ASCII
- Converting the octal bytes to ASCII reveals the final string.
- The decoding script used is below.
| |

Flag
The flag for this challenge is: nexsec25{513afc1272b40668995da3f69faeee5b37dd58beccc9fbf41cc3b44a58669de6}